

Если в XX веке нефть была двигателем индустриальной революции, то в эпоху искусственного интеллекта синтетические данные становятся топливом цифровой трансформации. Gartner прогнозирует, что к 2030 году до 60% данных для обучения ИИ-моделей будут синтетическими. Рынок синтетических данных демонстрирует взрывной рост: с $0.3 млрд в 2023 году до $19.22 млрд к 2035 году.
Ключевые выводы этого исследования показывают, что синтетические данные решают три критические проблемы современного ИИ: дефицит качественных данных, нарушения приватности и высокие затраты на сбор информации. Компании, внедрившие синтетические данные, сокращают время вывода продуктов на рынок на 35% и снижают затраты на данные на 70%.
Что такое синтетические данные
Синтетические данные — это искусственно созданная информация, которая имитирует статистические свойства и паттерны реальных данных, но не содержит фактических персональных или конфиденциальных сведений. В отличие от простой анонимизации, синтетические данные генерируются с нуля с использованием алгоритмов машинного обучения.
💡 Справка: Синтетические данные создаются с помощью генеративных моделей ИИ, которые изучают закономерности в исходных данных и затем создают новые образцы с аналогичными характеристиками.
Типы синтетических данных
Современные технологии позволяют генерировать различные форматы данных:
- Табличные данные — финансовые транзакции, медицинские записи, клиентские базы
- Текстовые данные — документы, отзывы, техническая документация
- Медиаданные — изображения, видео, аудиозаписи
- Временные ряды — сенсорные данные, метрики производительности
- Пространственные данные — геолокационная информация, карты
Почему синтетические данные — новая нефть
Аналогия с нефтью не случайна. Как сырая нефть требует переработки для получения полезных продуктов, так и сырые данные нуждаются в обработке для создания ценности. Синтетические данные представляют собой "очищенное топливо" для ИИ-систем.
Ключевые преимущества
| Преимущество | Описание | Процент_улучшения | Отрасль_применения |
|---|---|---|---|
| Защита конфиденциальности | Отсутствие персональных данных исключает риски утечек | 100% | Все отрасли |
| Снижение стоимости сбора данных | До 70% экономии на сборе и аннотировании данных | 70% | Здравоохранение, Финансы |
| Ускорение разработки ИИ | На 35% сокращает время вывода продукта на рынок | 35% | ИТ, Автопром |
| Устранение предвзятости | Позволяет создавать сбалансированные датасеты | 60% | Машинное обучение |
| Масштабируемость | Генерация любых объемов данных по требованию | Безлимитно | Все отрасли |
| Доступность данных | Решает проблему дефицита данных в специализированных областях | 300% | Медицина, Автономные системы |
| Соответствие нормативным требованиям | Упрощает соблюдение GDPR, CCPA и других регуляций | 80% | Банки, Страхование |
| Создание редких сценариев | Моделирование критических ситуаций без рисков | 500% | Автопром, Авиация |
Защита конфиденциальности стала критическим фактором в эпоху GDPR и растущих требований к приватности. Российские нефтяные компании, такие как "Газпром нефть" и "Транснефть", уже применяют ИИ для анализа геологических данных и оптимизации добычи. Синтетические данные позволяют им обучать модели без раскрытия коммерческой информации о месторождениях.
⚡ К 2030 году синтетические данные помогут компаниям избежать 70% санкций за нарушение приватности, сократив потребность в сборе персональных данных клиентов.
Технологии генерации синтетических данных
Революция в синтетических данных стала возможной благодаря прорывам в генеративном ИИ. Лидирующие технологии демонстрируют различную эффективность в зависимости от типа задач.
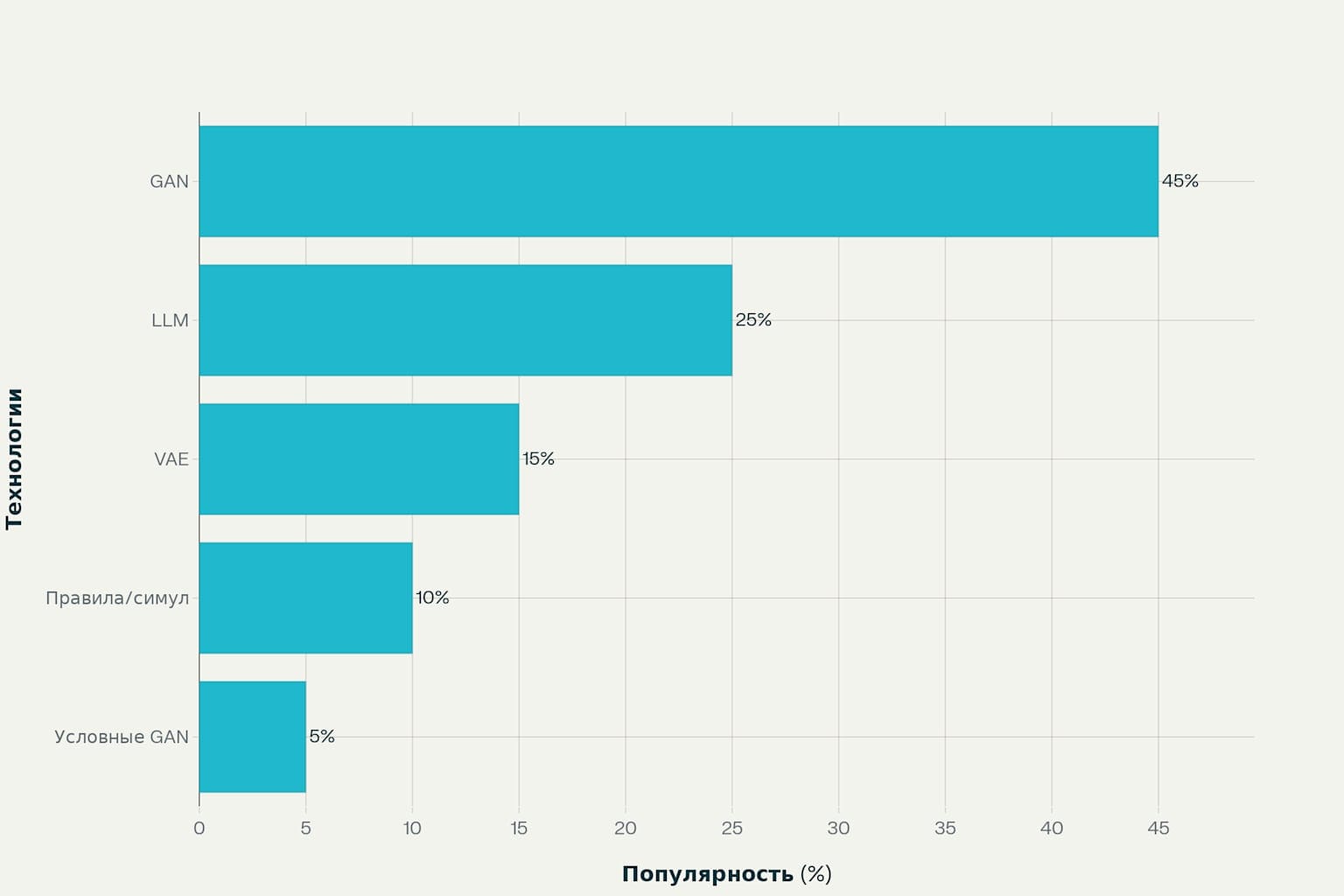
Generative Adversarial Networks (GAN) доминируют на рынке с 45% долей благодаря способности создавать высокореалистичные данные. Принцип работы основан на состязании двух нейросетей: генератора и дискриминатора, что обеспечивает высокое качество синтетических образцов.
Large Language Models (LLM) занимают 25% рынка и особенно эффективны для текстовых данных. Современные LLM могут генерировать синтетические тексты, имитирующие медицинские заключения, юридические документы или техническую документацию.
Статистика: 67% технологических компаний используют синтетические данные в разработке, что в три раза больше, чем в 2019 году.
Методы оценки качества
Критический аспект синтетических данных — обеспечение их статистической достоверности:
- Fidelity (точность) — насколько близко синтетические данные воспроизводят распределения исходных
- Utility (полезность) — сохранение аналитической ценности для конкретных задач
- Privacy (приватность) — отсутствие возможности восстановить исходную информацию
Отраслевое применение
Различные отрасли демонстрируют неравномерную готовность к внедрению синтетических данных, что отражает специфику их потребностей в данных и регуляторных требований.
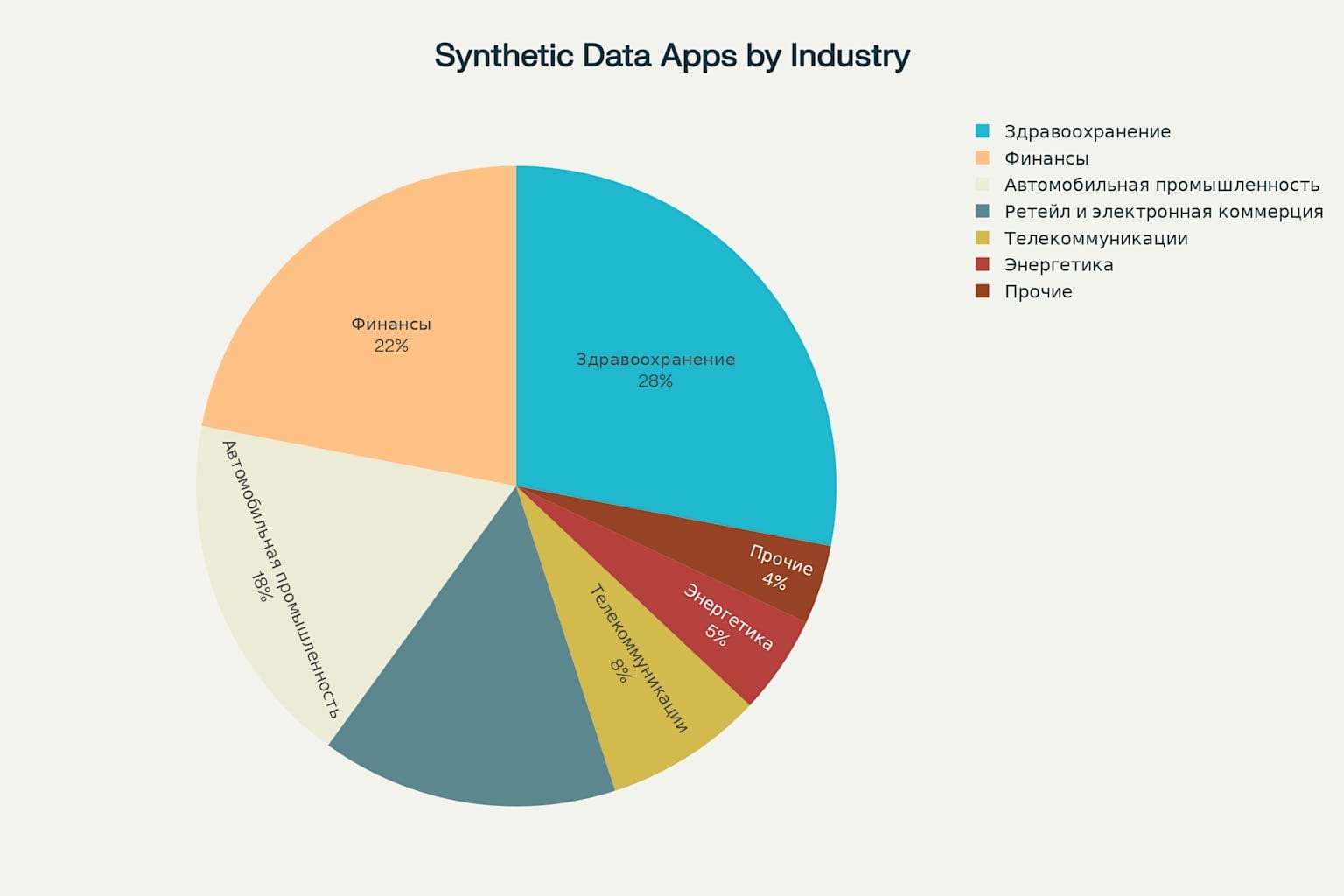
Здравоохранение (28%) лидирует из-за критической важности защиты медицинских данных. Синтетические медицинские записи позволяют исследователям разрабатывать диагностические алгоритмы без нарушения врачебной тайны.
Финансовый сектор (22%) использует синтетические данные для обучения систем выявления мошенничества. Американский банк American Express применяет синтетические транзакционные данные для улучшения алгоритмов детекции fraudа.
Автомобильная промышленность (18%) генерирует синтетические сценарии вождения для обучения автономных систем. Waymo создает "полностью синтетические данные в масштабе реального мира" для ускорения разработки беспилотных автомобилей.
Пример: Tesla использует синтетические данные для виртуального обучения автопилота, моделируя миллионы дорожных ситуаций без риска для безопасности.
Вызовы и ограничения
Несмотря на впечатляющий потенциал, синтетические данные сталкиваются с серьезными техническими и этическими вызовами.
Технические ограничения
Проблема качества остается центральной. Исследования показывают, что синтетические данные могут не обеспечивать лучшего компромисса между приватностью и полезностью по сравнению с традиционными методами анонимизации.
Потеря выбросов — синтетические модели часто не воспроизводят редкие события, которые могут быть критичными для некоторых исследований.
Этические и правовые аспекты
Алгоритмическая предвзятость может усиливаться в синтетических данных, если исходные данные содержали искажения. Компании должны внедрять строгие процедуры аудита для выявления и устранения таких проблем.
⚠️ Регулирование синтетических данных находится в стадии формирования. EU AI Act и подобные инициативы начинают устанавливать требования к прозрачности и подотчетности ИИ-систем.
Будущее синтетических данных
Эволюция синтетических данных определяется несколькими ключевыми трендами, которые сформируют рынок до 2030 года и далее.
| Год | Размер_рынка_млрд_USD | CAGR_% | Прогноз_Gartner_%_AI_данных_синтетических | Основные_драйверы |
|---|---|---|---|---|
| 2023 | 0.3 | - | 10 | Начальный этап |
| 2024 | 0.5 | 66.7 | 18 | COVID-19, приватность |
| 2025 | 0.8 | 60.0 | 35 | Регуляции GDPR |
| 2026 | 1.2 | 50.0 | 45 | Развитие GAN/LLM |
| 2027 | 1.8 | 50.0 | 55 | Масштабирование ИИ |
| 2028 | 2.1 | 16.7 | 60 | Корпоративное внедрение |
| 2030 | 2.3 | 9.5 | 60 | Зрелость технологий |
| 2034 | 13.0 | 45.7 | 80 | Доминирование в ИИ |
| 2035 | 19.22 | 48.0 | 90 | Повсеместное принятие |
Доминирование в обучении ИИ становится реальностью. По прогнозам, к 2030 году синтетические данные составят более 95% данных для обучения моделей компьютерного зрения. Это кардинально изменит подходы к разработке ИИ-систем.
Технологические прорывы
Synthetic Data as a Service (SDaaS) — облачные провайдеры расширяют предложения по генерации кастомных синтетических датасетов по требованию. Это демократизирует доступ к высококачественным данным для малых и средних компаний.
Специализированные генеративные модели заменяют универсальные решения. Ожидается появление доменно-специфичных генераторов для здравоохранения, финансов, автономных систем и других отраслей.
Прогноз: К 2027 году синтетические данные будут составлять 55% всех данных для обучения ИИ, а объем рынка достигнет $1.8 млрд.
Интеграция с новыми технологиями
Quantum-enhanced generation — квантовые вычисления могут революционизировать качество и скорость генерации синтетических данных.
Blockchain validation — технология блокчейн обеспечит прозрачность и подотчетность в процессах генерации и валидации синтетических данных.
Синтетические данные трансформируются из экспериментальной технологии в основной ресурс разработки ИИ. Статистика убедительна: 67% внедрения среди техкомпаний, 35% ускорения time-to-market, 47% снижения затрат и множественные улучшения качества подтверждают бизнес-ценность этого подхода.
Аналогия с нефтью отражает фундаментальную роль данных в цифровой экономике. Как нефть питала индустриальный рост XX века, синтетические данные становятся топливом ИИ-революции XXI века. Компании, которые освоят эту технологию, получат конкурентные преимущества в мире, где данные определяют успех инноваций.
Ключевой вызов ближайших лет — балансирование между техническими возможностями и этическими требованиями. Только при ответственном подходе синтетические данные реализуют свой потенциал как "новая нефть эпохи ИИ", обеспечивая устойчивое развитие искусственного интеллекта без компромиссов в области приватности и безопасности.





